
进入信息时代,保存在计算机中的文件和数据量正在以指数速度增长,同时人们期望从数据中获得更有用的信息。实际上,这些数据中只有一小部分有用,但人们却渴求获得知识,正面临“数据丰富而知识贫乏”的问题,所以迫切需要一种新的技术从海量数据中自动、高效的提取所需要的有用知识,这时,数据挖掘技术由此而生。
数据挖掘是一个以数据库、人工智能、数理统计、可视化四大支柱技术为基础,我们知道,描述或说明一个算法设计分为三个部分:输入、输出和处理过程。数据挖掘算法的输入是数据库,算法的输出是要发现的知识或模式,算法的处理过程则设计具体的搜索方法。从算法的输入、输出和处理过程三个角度分,可以确定数据挖掘主要涉及三个方面:挖掘对象、挖掘任务、挖掘方法。挖掘对象包括若干种数据库或数据源,例如关系数据库、面向对象数据库、空间数据库、时态数据库、文本数据库、多媒体数据库、历史数据库,以及万维网(WEB)等。挖掘方法可以粗分为:统计方法、机器学习方法、神经网络方法和数据库方法。统计方法可细分为:回归分析、判别分析等。机器学习可细分为:遗传算法等。神经网络方法可细分为:前向神经网络、自组织神经网络等。数据库方法主要是多维数据分析方法等。
数据挖掘技术是一个多步骤、可能需多次反复的处理过程。主要包括以下几步:准备、数据选择、数据预处理、数据缩减、确定数据挖掘的目标、确定知识发现算法、数据挖掘(Data Mining)、模式解释、知识评价。其中最重要的一个步骤是数据挖掘,它是利用某些特定的知识发现算法,在可接受的运算效率的限制下,从有效数据中发现有关的知识。
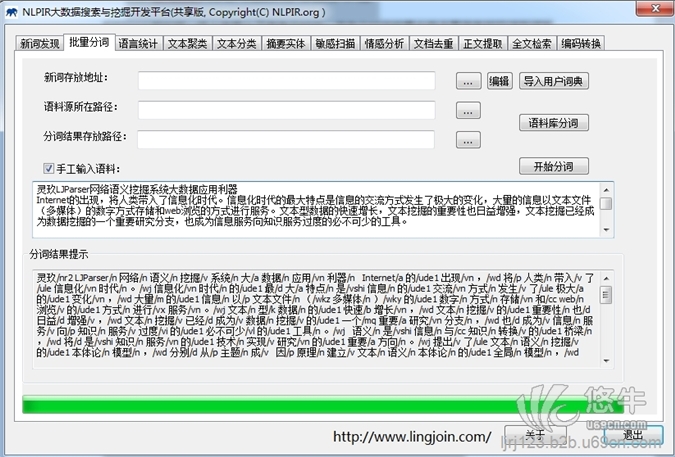
灵玖软件NLPIR大数据语义智能分析平台针对中文数据挖掘的综合需求,融合了网络精准采集、自然语言理解、文本挖掘和语义搜索的研究成果,先后历时十八年,服务了全球四十万家机构用户,是大时代语义智能分析的一大利器。
NLPIR大数据语义智能分析平台平台针对互联网内容处理的需要,融合了自然语言理解、网络搜索和文本挖掘的技术,提供了用于技术二次开发的基础工具集。
NLPIR能够全方位多角度满足应用者对大数据文本的处理需求,包括大数据完整的技术链条:网络采集、正文提取、中英文分词、词性标注、实体抽取、词频统计、关键词提取、语义信息抽取、文本分类、情感分析、语义深度扩展、繁简编码转换、自动注音、文本聚类等。
“大数据”的本质实际上是数据生产的社会化,其对统计尤其是政府统计的冲击是重大的,不仅涉及到整个统计流程,更加对当前的政府统计管理体制、机构设置、数据价值等方面形成了挑战。可以大胆预测,未来政府统计的政府角色会被统计专业性取代,经济分析的职能会被更为专业的经济分析部门取代,宏观数据的重要性会让位于更有信息价值的微观数据。
数据挖掘技术是一个发展十分快的领域, 随着对数据挖掘技术在各领域日益广泛的应用,实现了数据资源共享及技术发展的跨域,从而大大提高了工作效率,并带来巨大的成功。